Text Classification Using Mixture Models
Mixture ModelsThe usage of finite mixtures for class-conditional probability functions is a useful method in pattern recognition, because mixture models are able to represent arbitrarily complex probability functions. Mixtures are flexible enough for finding an appropriate tradeoff between model complexity and the amount of the training data available.Our approach to learning on text document is based on the fact that documents in the same class are often mixtures of multiple topics. Although mixture models are important for continuous data, some research shows, that these models perform, with discrete data in text classification, very well too. We focus on the application of the mixture of multivariate Bernoulli distributions Bernoulli mixture model and on the mixture of multinomial distributions Multinomial mixture model. The estimation of mixture parameters is done by EM-algorithm. For performance evaluation, we carried out the experiments with the Reuters-21578 data collection and the Newsgroups data set |
|
 |
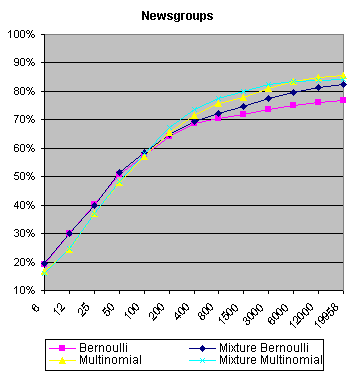 |
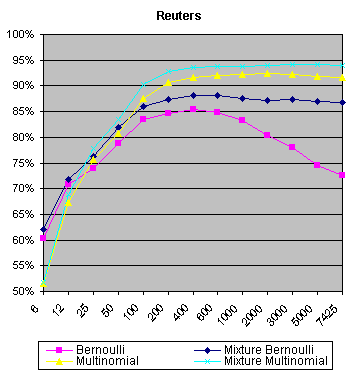
| Experimental results on the Reuters and the Newsgroups data sets indicate the effectiveness of the multinomial mixture model.
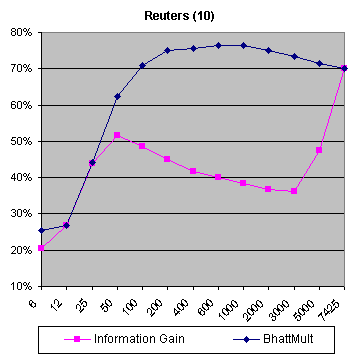
Bernoulli mixture and multinomial mixture models have been used as class-conditional models for the task of text document classification to relax the naive Bayes class-conditional independence assumption. This generalization of naive Bayes tries to properly model significant class-conditional dependencies by spreading them over different mixture components. An observation of the performance of Bayes classifier for text classification on Reuters-21578 and Newsgroups data sets suggests that learning methods based on Bernoulli mixture and multinomial mixture models for class-conditional probability functions of the documents performed better than the corresponding standard models. Feature SelectionWe propose to use the multiclass Bhattacharrya distance (MBD) for multinomial model as a feature selection criterion to measure the ability of feature subsets in discriminating between classes and to take into consideration how features work together (opposed to information gaincriterion).The performance of FS on small training sets was observed. We used a few documents for training the multinomial model; ten documents from each class of the Reuters data set and hundred documents from each class of the Newsgroups data set. The rest of documents was employed for testing. |
|
 |
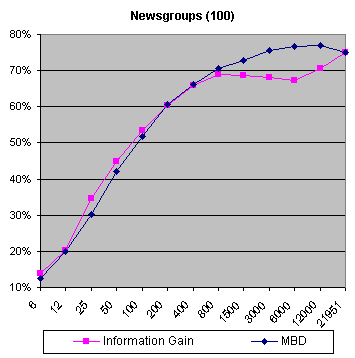 |
| The behaviour of both methods on Reuters data set is similar on an extremely small number of words (less than 25) but after this point the classification accuracy of MBD is considerably higher. | |